
Departure
Google Home Mini used to flip the lights when I asked. Then the family stopped paying for the subscription and the bridge to our Universal Devices ISY went silent — the lights remembered who used to ask but couldn't hear me anymore. I wanted the room back, but on better terms: no wake word, always listening, picking up commands the way a person in the room would. Lights, music, a clean iPad on the wall acting like a mirror. Build the assistant I wished Google had become.
Approach
- SwiftUI
- Gemini Live
- Gemini 2.0 Flash Thinking
- Llama 3.2:3b
- Fast Whisper
- Orpheus TTS
- Spotipy
- ISY REST
- Random Forest
No wake word — voice activation has to come from the room, and the loop has to be fast enough to feel like conversation.
Field log
Google Home Mini used to flip the lights when I asked. Family stopped paying for the subscription, the bridge to our Universal Devices ISY went silent, and the room forgot how to listen.
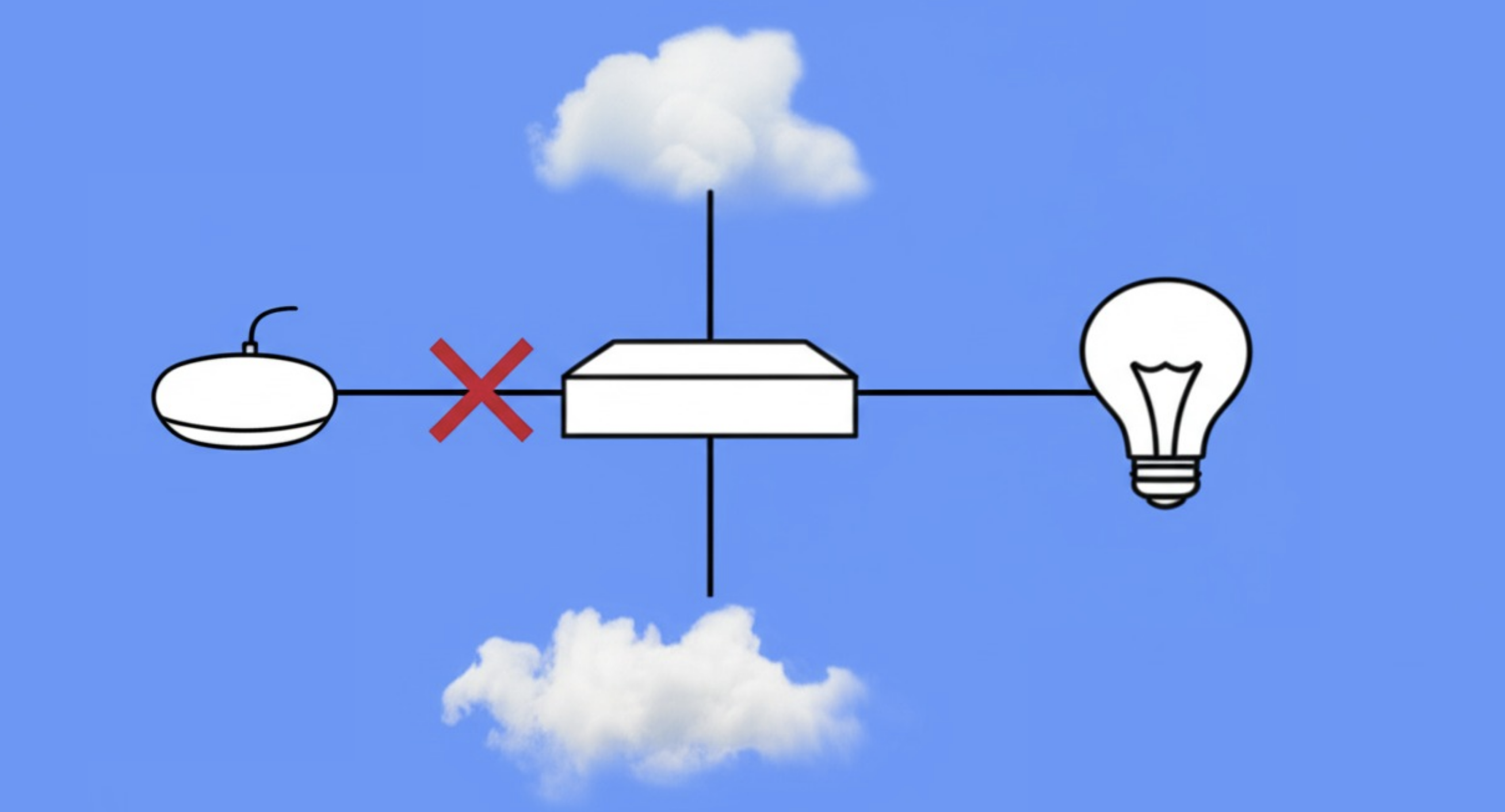
The link that died. No keyword. Automatic recognition — is it being spoken to, how many commands. Lights, music, and a clean iPad on the wall as the surface.
Streaming mic into speech-to-text, into an LLM, then out through two routes: function calls for the room and text-to-speech back to the user. Magic, but plumbed.
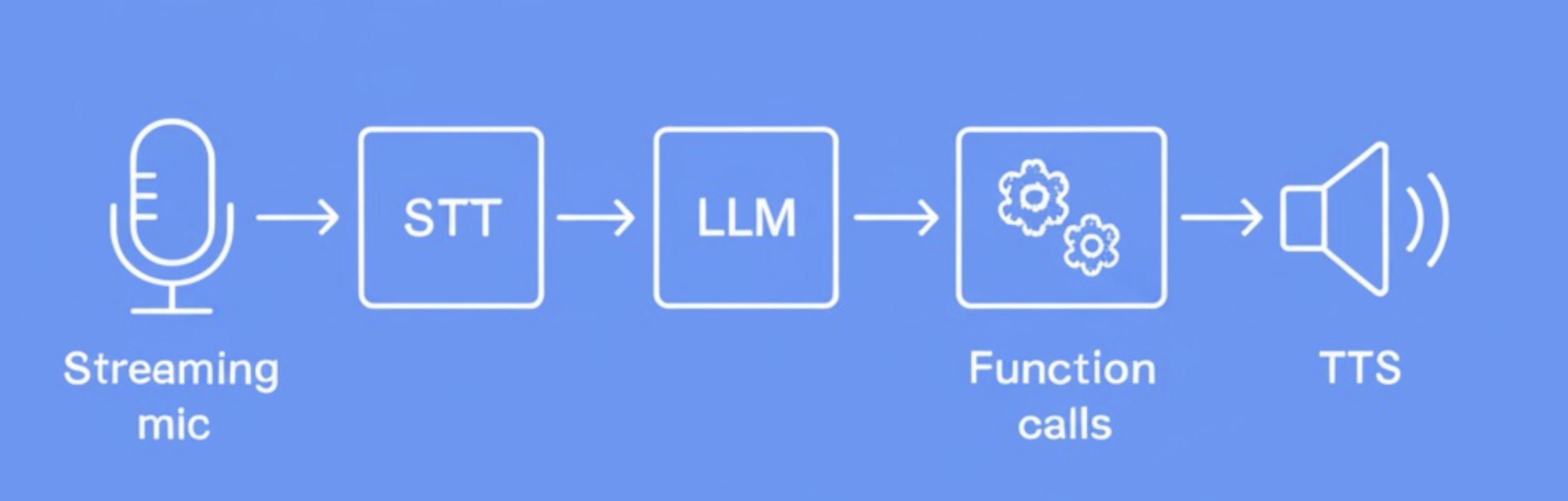
Mic in, function calls and voice out. The Universal Devices ISY exposes a REST API — get and set against an XML node tree. Could've wired the whole house, but went with what the assistant would actually need to reach: room, lamp, hallway, bathroom.
PyChromecast first, since the old Google Homes already spoke that language — but it couldn't pick songs by name. Switched to Spotipy 2.25.1, OAuth'd into my account, pointed playback at the speaker group I'd labeled Josh's Group years ago.
Latency was the gap between assistant and presence. Split voice activation into two parallel tracks — Llama 3.2:3b on the spoken-response track ("yeah, on it"), Gemini 2.0 Flash Thinking on the function-call track. The room could answer out loud while Gemini was still deciding what to actually do.
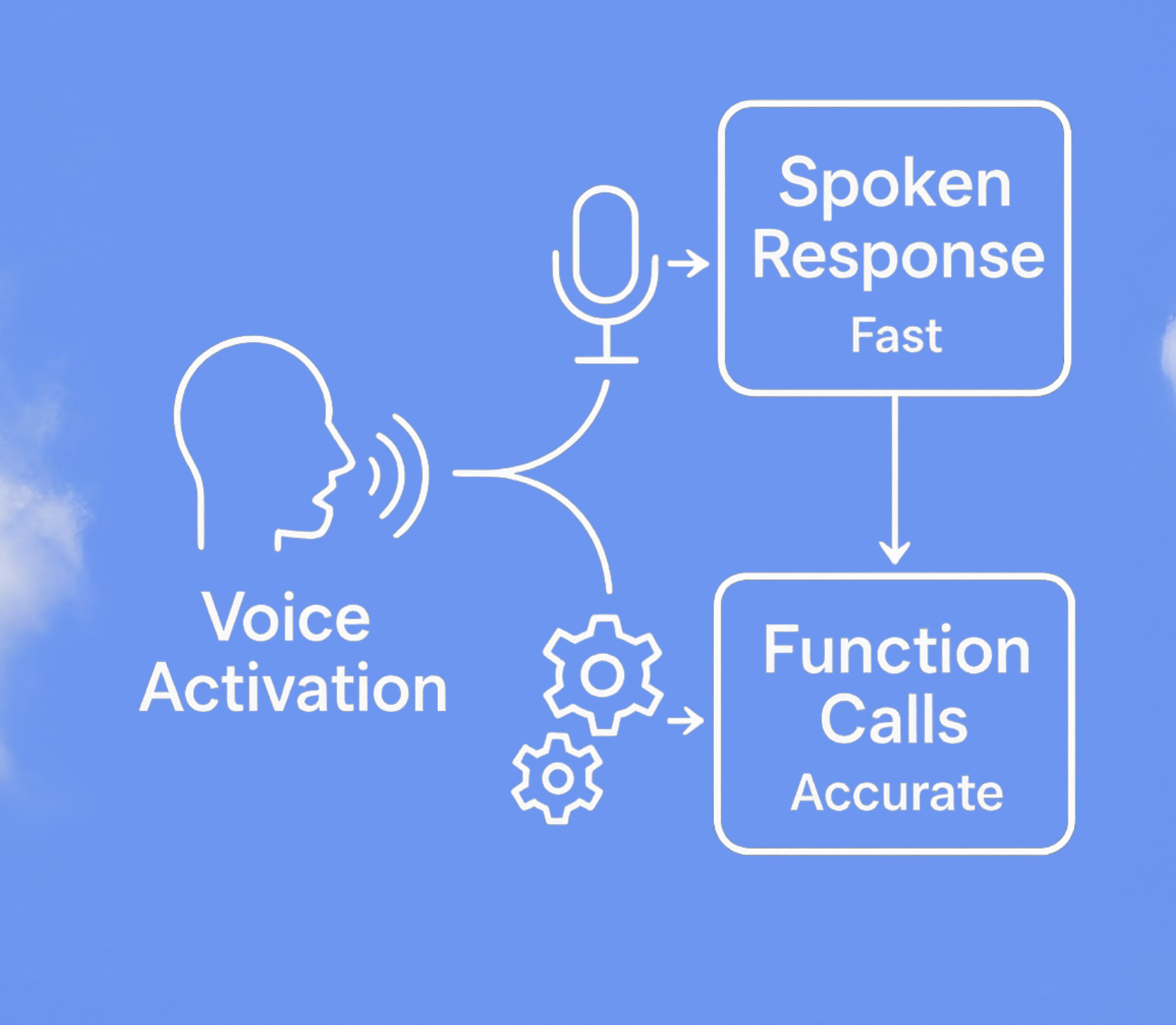
Fast response track, accurate action track. Whisper is the state of the art. Faster-Whisper is the open-sourced fork that other people made faster. About 150 ms response time — quick enough that turn-taking starts to feel like a conversation instead of a query.
Llama 3.2:3b on the response track is small and not particularly smart — but for "yeah, got it" and "alright, doing that now," small and fast is exactly what the route needs. Gemini 2.0 Flash Thinking carries the function calls. The spoken responses can be a little off; the function calls are perfect.
Tried Nari Dia 1.6B first — expressive, but too slow for a voice that's supposed to interrupt itself. Orpheus TTS gave back a balance, plus inline tags for laugh, chuckle, and breath that nudge it past flat-affect synthesis.
Inspired by Siri's redesign — the gradient border around the screen edge that pulses with whatever's being spoken. Mounted the iPad on the wall as a mirror with the live camera feed underneath, gradient on top, and a small dark debug terminal overlaid in the corner so I could watch what it was hearing.
Demo from the iPad mounted on the wall, gradient border pulsing with the audio. "Can you turn off my hallway lights?" — hallway clicks off through the doorway. "And turn off my room lights too." — overhead goes dark. "Can you play Stereo Love on Spotify?" — Spotipy pushes through Josh's Group, and Edward Maya fills the room.
End of the talk, no slide. Raised a hand: "Okay, turn off my lamp." The lamp behind me clicked off. Mic drop without the mic.
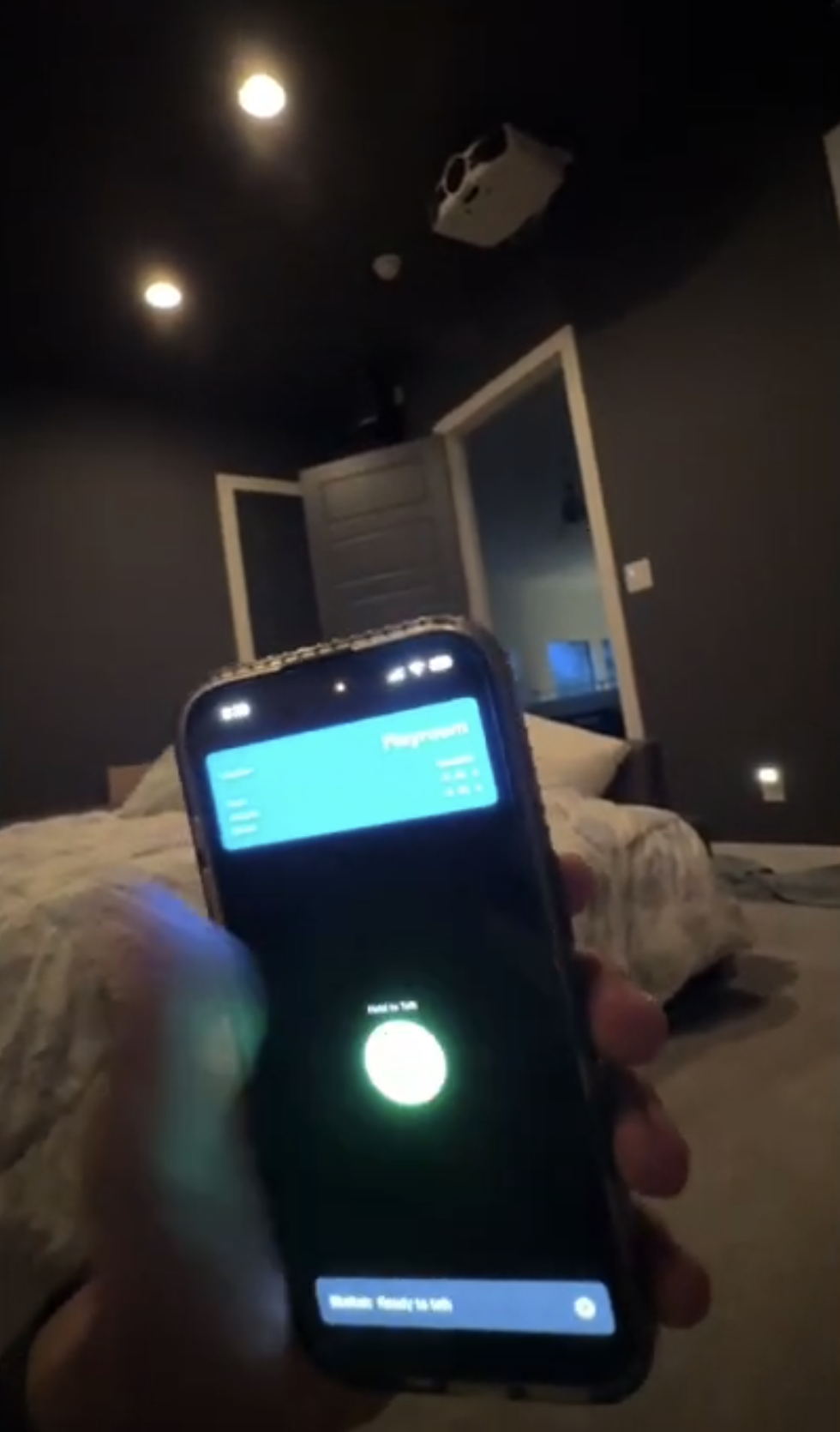
The live-control proof: phone interface up, bedroom lights responding. Showed gapi v1 to a friend. Truitt: "really built jarvis just for a school project." Took that as the sign v1 wasn't enough — v2 should be proactive, know where I am, see my emails, control music.
Next page of the spiral notebook had a robot labeled Gemini standing between two speakers labeled System Input and User Input. The router fed it from the internet — void, chromecast, macbook, iphone — all running into the same listener.

v2, page one: Gemini as the box between system input and user input. Gemini at the center, surrounded by what it had to talk to — Universal Devices for the lights, Google APIs for everything Google, VLC and Google Cast for playback, Scikit-Learn for the presence model, Python on the server side, Swift on the iPad.
Swapped the v1 STT-LLM-TTS chain for a single WebSocket to the Gemini Live API. Text, audio, and video out; text and audio back. One connection, real-time, no stitching three models together to fake the cadence.
First attempt at presence detection: emit iBeacon advertisements from a Bluetooth card and triangulate from fixed receivers. The card refused to output the format. Spent days on it, never got a frame out.
Switched approaches. An iPhone app scanned every nearby MAC + dBm reading, labeled each scan by the room I was standing in (Bedroom, Media, Playroom), and POSTed to a tiny server in a constant stream. Four days of data later — RandomForestClassifier 99.7%, KNeighborsClassifier 98.6%, LinearSVC 98.0%. Live prediction came back Playroom 96 / Media 4 / Bedroom 0.
Confusion matrix only ever mixed Playroom with Media — the two rooms that share a wall. The Bluetooth signal couldn't tell which side of the drywall I was on, and honestly neither could I half the time.
Closing slide: a Wii console box, repackaged. Same proportions, same white plastic, same translucent play button — relabeled 'Gemi' on the console and 'Gemini Smart Home' on the box. The product the room had quietly become.
From the gallery
What I came back with
Lesson from the terrain
Latency was the gap between an assistant and a presence in the room. Splitting the response into a fast Llama track and an accurate Gemini track meant the room could answer while it was still figuring out what to do — closer to how a person responds than how an API does. The iPad-as-mirror was the other half: not a screen you summon, but a surface that's always there, pulsing back at you when it hears you.